
2026. 1. 11. 16:14ㆍHow to become a real programmer/Projects
안녕하십니까. 네 좋은 주말입니다. 껄껄.
금연 앱 'NoSmoke'의 AI 채팅 기능을 만들고 신나게 테스트를 하던 중이었습니다. 처음엔 채팅 메시지가 10개, 20개뿐이라 아무 문제가 없었죠.
그런데 문득 "사용자가 금연을 1년 동안 해서 채팅 데이터가 10만 개가 쌓이면 어떻게 되지?"라는 호기심이 발동했습니다. 그래서 더미 데이터 10만 건을 DB에 들이붓고 채팅방에 입장해 봤습니다.

결과는?
앱이 멈췄습니다. 서버 로그를 보니 메모리가 출렁거리고 난리가 났더군요.
오늘은 무식하게 다 가져오던(FindAll) 습관을 버리고, 필요한 만큼만 가져오는(Slice) 다이어트 과정을 기록해 봅니다.
1. 상황 분석 : 코끼리를 냉장고에 넣으려고 했다
기존 로직은 아주 단순했습니다. 사용자가 채팅방에 들어오면, "저 사람의 모든 기록을 가져와!"라고 DB에 외쳤죠.
[AS-IS: 전체 조회 방식]
Client: 나 들어왔어! 내 채팅 내역 주쇼잉
Server: (DB에서 10만 줄을 전부 읽어서 리스트에 담음) -> 자, 여기 10만 개! 용량은 10MB야!
Client: 돌았나 이거.. 꿱 (메모리 부족으로 버벅거림)
문제는 명확합니다. Postman으로 호출해봤는데요. 다음과 같은 문제가 명확합니다.
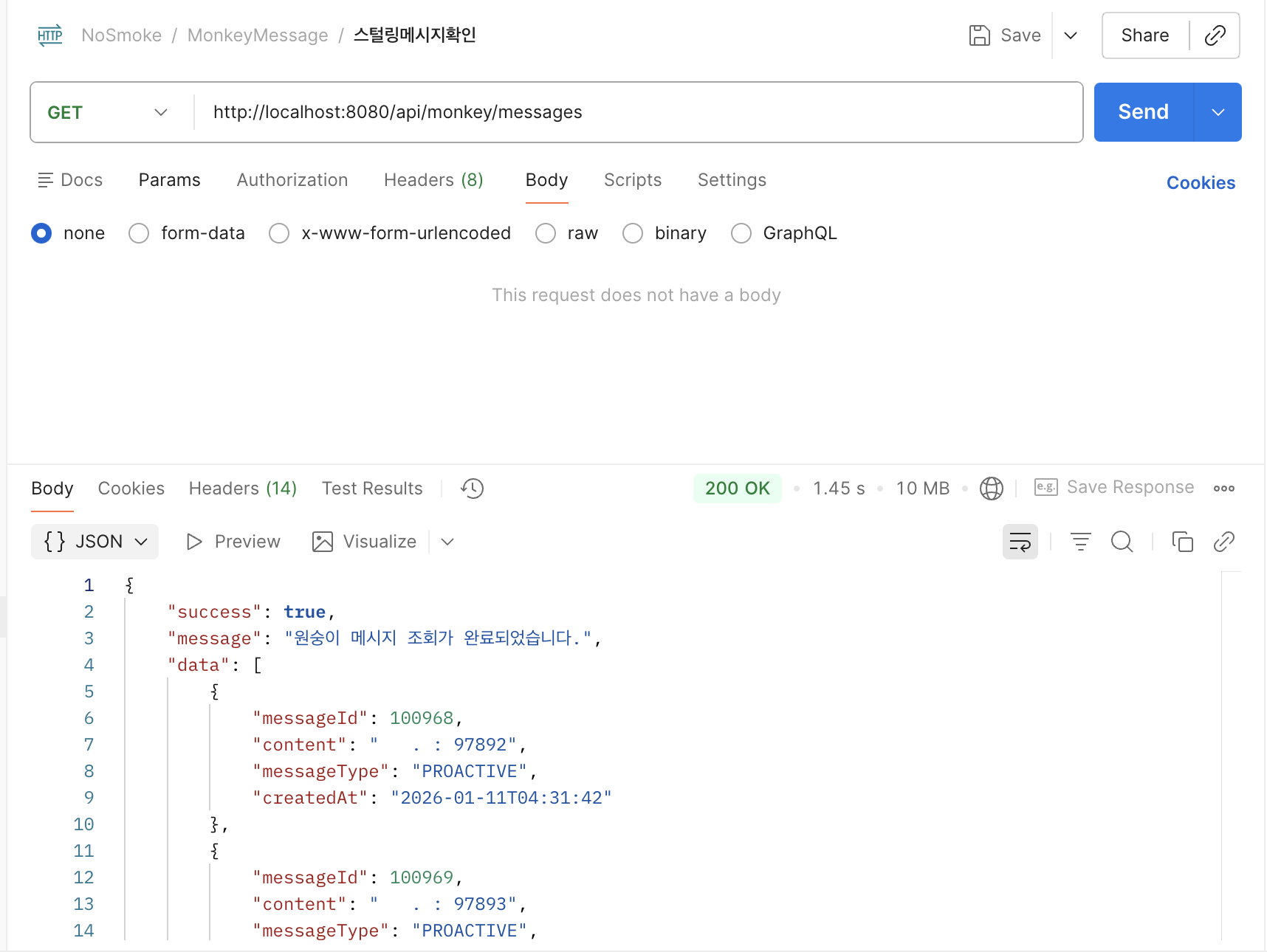
- 속도 저하: 10만 건을 조회해서 응답하는 데 1.45초나 걸립니다. 채팅 앱에서 1초 넘는 로딩은 "렉 걸렸네" 소리 듣기 딱 좋죠.
- 리소스 낭비: 텍스트 데이터라 가벼울 줄 알았는데, 한 번 조회에 10MB를 차지합니다. 동시 접속자 100명이면? 순식간에 1GB 메모리가 증발합니다. OOM(Out Of Memory) 예약인 셈이죠.
우리는 카카오톡을 볼 때 3년 전 대화부터 보지 않습니다. "가장 최근 대화"부터 보고, 궁금하면 위로 올려보죠.
네, Pagination(페이징)이 필요한 시점입니다.
2. 전략 수립 : Page vs Slice
Spring Data JPA에서 페이징을 처리하는 방법은 크게 두 가지가 있습니다. Page와 Slice입니다.
- Page<T>: 데이터 내용물 + 전체 페이지 수(Total Count)를 같이 줍니다. (예: 게시판 1, 2, 3... 10 페이지)
- Slice<T>: 데이터 내용물 + "다음 장 있어?(hasNext)" 정보만 줍니다. (예: 인스타그램, 카카오톡 무한 스크롤)
채팅방에 "총 5,321페이지 중 1페이지"라는 정보가 필요할까요? 아닙니다.
그저 스크롤을 올렸을 때 과거 내용이 더 있는가? 만 알면 됩니다.
게다가 Page를 쓰면 전체 데이터 개수를 세는 Count Query가 무조건 나갑니다. 데이터가 많아질수록 이 카운트 쿼리는 DB의 목을 조르게 됩니다.
그래서 저는 Count 쿼리 없이 가볍고 빠른 Slice! 를 선택했습니다.
3. 코드 구현 : 다이어트 시작
백엔드 로직을 수정했습니다. List를 반환하던 녀석을 Slice로 바꾸고, Pageable을 적용했습니다.
[MonkeyMessageRepository]
전
package org.example.nosmoke.repository;
import org.example.nosmoke.entity.MonkeyMessage;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface MonkeyMessageRepository extends JpaRepository<MonkeyMessage, Long> {
// monkey message가 가진 user 필드의 id를 조건으로 생성시간 기준 내림차순(최신순)으로 검색하겠다
List<MonkeyMessage> findByUser_IdOrderByCreatedAtDesc(Long userId);
}
후
package org.example.nosmoke.repository;
import org.example.nosmoke.entity.MonkeyMessage;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Slice;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface MonkeyMessageRepository extends JpaRepository<MonkeyMessage, Long> {
// Slice로 반환
// 쿼리 실행 시 limit + 1개를 가져와서 다음 페이지 존재 여부만 체크한다(Count 쿼리가 안나간다)
Slice<MonkeyMessage> findByUser_IdOrderByCreatedAtDesc(Long userId, Pageable pageable) ;
}
여길 바꾸니 서비스 로직도 바꿔야 하더군요.
[MonkeyService]
전
@Slf4j
@Component
@RequiredArgsConstructor
public class MonkeyFacade {
private final MonkeyService monkeyService;
private final AiService aiService;
// 채팅 기능
public String chatWithSterling(Long userId, String userMessage){
MonkeyChatContextDto context = monkeyService.getChatContext(userId);
String prompt = monkeyService.createPersonPrompt(context, userMessage);
String aiResponse = aiService.generateResponse(prompt);
try {
monkeyService.saveMessage(userId, aiResponse, MonkeyMessage.MessageType.REACTIVE);
} catch (Exception e) {
log.error("AI 응답 저장 실패 (유저: {}): {}", userId, aiResponse);
}
return aiResponse;
}
// 건강 분석 기능
... 패스
// 메세지 조회
public List<MonkeyMessage> findMessagesByUserId(Long userId) {
return monkeyService.findMessagesByUserId(userId);
}
}
후
@Service
@Transactional(readOnly = true)
@RequiredArgsConstructor
public class MonkeyService {
private final MonkeyMessageRepository monkeyMessageRepository;
private final UserRepository userRepository;
private final SmokingInfoRepository smokingInfoRepository;
// 정보 조회
public MonkeyChatContextDto getChatContext(Long userId){
User user = userRepository.getByIdOrThrow(userId);
SmokingInfo smokingInfo = smokingInfoRepository.getByUserIdOrNull(userId);
return new MonkeyChatContextDto(user, smokingInfo);
}
// 채팅용 프롬프트 생성
... 패스
// 건강 분석용 프롬프트 생성
... 패스
// 메시지 저장(쓰기 트랜잭션)
... 패스
// 메시지 조회
public Slice<MonkeyMessage> findMessagesByUserId(Long userId, int page, int size){
Pageable pageable = PageRequest.of(page,size);
return monkeyMessageRepository.findByUser_IdOrderByCreatedAtDesc(userId, pageable);
}
}
[MonkeyFacade]
전
@Slf4j
@Component
@RequiredArgsConstructor
public class MonkeyFacade {
private final MonkeyService monkeyService;
private final AiService aiService;
// 채팅 기능
public String chatWithSterling(Long userId, String userMessage){
MonkeyChatContextDto context = monkeyService.getChatContext(userId);
String prompt = monkeyService.createPersonPrompt(context, userMessage);
String aiResponse = aiService.generateResponse(prompt);
try {
monkeyService.saveMessage(userId, aiResponse, MonkeyMessage.MessageType.REACTIVE);
} catch (Exception e) {
log.error("AI 응답 저장 실패 (유저: {}): {}", userId, aiResponse);
}
return aiResponse;
}
// 건강 분석 기능
... 패스
// 메세지 조회
public List<MonkeyMessage> findMessagesByUserId(Long userId) {
return monkeyService.findMessagesByUserId(userId);
}
}
후
@Slf4j
@Component
@RequiredArgsConstructor
public class MonkeyFacade {
private final MonkeyService monkeyService;
// Facade 에서 이제 더이상 AI를 직접 부르지 않아도 되기에 AiService가 아닌 RabbitTemplate 부름
private final RabbitTemplate rabbitTemplate;
private final SimpMessagingTemplate messagingTemplate;
private final TaskScheduler taskScheduler;
// 채팅 기능
public String chatWithSterling(Long userId, String userMessage){ // 성능 개선해야
// 유저 메시지 DB에 저장
monkeyService.saveMessage(userId, userMessage, MonkeyMessage.MessageType.USER);
// DB 에서 채팅 조회
MonkeyChatContextDto context = monkeyService.getChatContext(userId);
String prompt = monkeyService.createPersonPrompt(context, userMessage);
rabbitTemplate.convertAndSend(
RabbitMqConfig.EXCHANGE_NAME,
RabbitMqConfig.ROUTING_KEY,
new MonkeyAiRequestEvent(userId, prompt)
);
log.info(">>> AI 요청 큐 발행 완료 (User: {}) ", userId);
return "스털링이 고민을 시작했습니다...";
}
// 건강 분석 기능
... 패스
// 웰컴 메시지
... 패스
// 메세지 조회
public Slice<MonkeyMessage> findMessagesByUserId(Long userId, int page, int size) {
return monkeyService.findMessagesByUserId(userId, page, size);
}
}
후, 조회하는 부분을 요렇게 다 바꿨네요.
프론트인 플러터도 바빠졌습니다.
스크롤이 천장(Top)에 닿으면, 다음 페이지(과거 데이터)를 불러오도록 ScrollController를 심었습니다.(요건 Gemini가 해줬기에 패스)
4. 결과 분석
수정을 마치고 다시 10만 건 데이터 환경에서 테스트를 돌렸습니다. Postman으로 API를 쏘고 보니 아주 나이스해졌습니다.
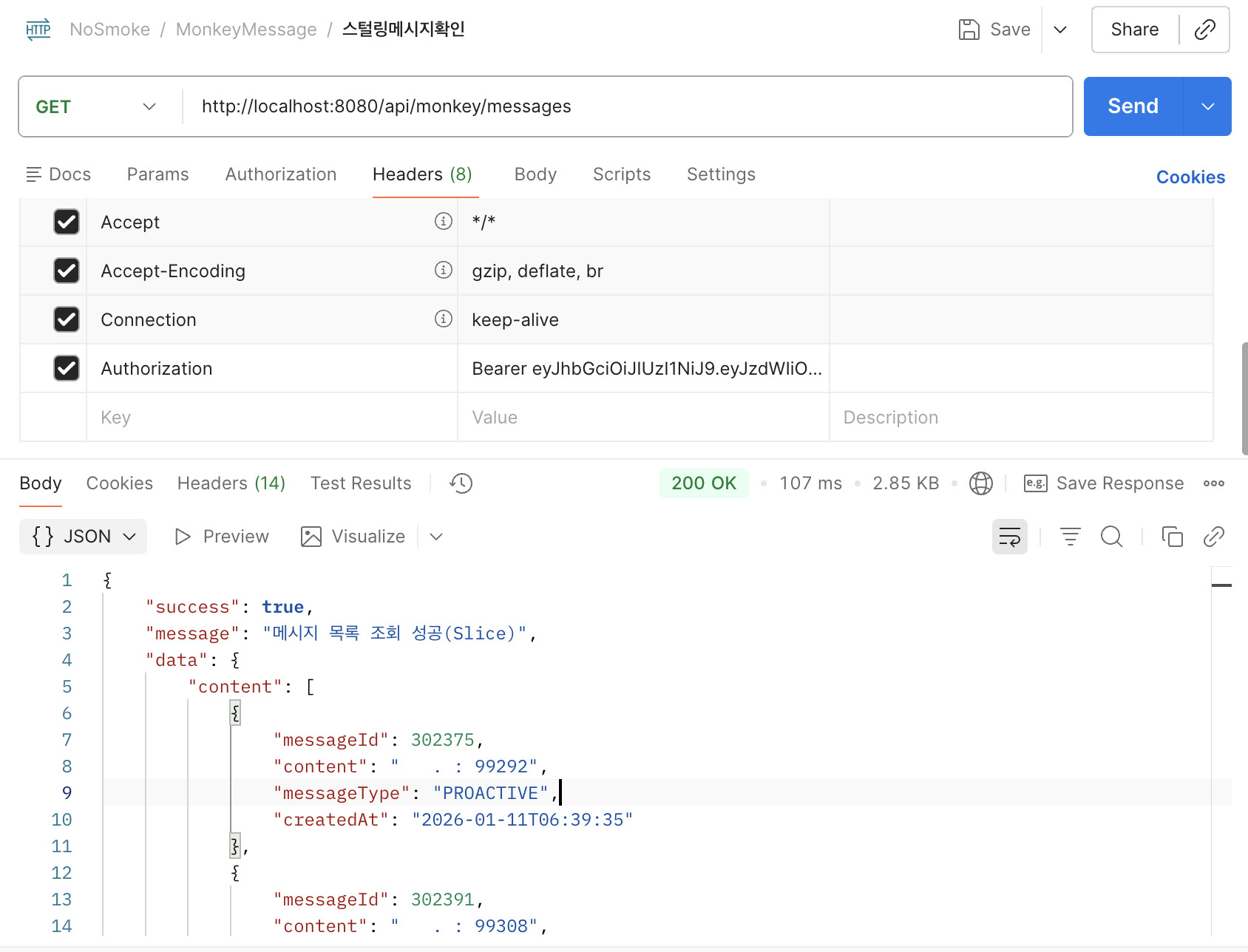
- 응답 속도: 1.45s => 0.107s (약 13.5배 빨라짐)
- 눈 깜짝할 새도 안 되는 시간에 데이터가 날아옵니다.
- 데이터 크기: 10MB => 2.85KB (약 3,500배 감소)
- 3,500배 다이어트라니... 100kg 사람이 28g이 된 격입니다. 너무 지피티식 표현인가요? 네트워크 비용이 획기적으로 줄었습니다.
모바일로도 확인해보니

잘 불러와지네용.
이제 서버는 10만 개의 짐을 한 번에 짊어지는 게 아니라, 딱 20개씩 가볍게 배달합니다.

메모리 사용량도 안정적인 수평선을 그리게 되었습니다.
5. 결론 : 당연한 것을 당연하게 만들기
사실 페이징은 웹 개발의 기초 중 하나입니다. 하지만 "기능이 돌아가니까"라는 이유로 findAll()을 방치했다면, 나중에 사용자가 몰렸을 때 서버비 폭탄을 맞거나 앱이 다운되었을 겁니다.
이번 트러블 슈팅을 통해 두 가지를 확실히 챙겼습니다.
- Slice의 위력: 불필요한 Count 쿼리만 없애도 DB가 행복해한다.
- 꺼진 불도 다시보자 : 기능 구현이 다가 아니네요. 기능 구현이 시작이었구나.. 싶습니다.
이제 스털링(챗봇)은 아무리 대화가 길어져도, 0.1초 만에 과거의 기억을 꺼내올 수 있게 되었습니다. 오예~
- Q&A -
Q. 왜 Offset 방식(Page number)을 썼나요? No-Offset이 더 빠르지 않나요? :
맞습니다. 현재는 Pageable을 이용한 Offset 기반의 Slice입니다 (LIMIT 20 OFFSET 200 방식).
데이터가 수백만, 수천만 건으로 넘어가면 앞부분의 데이터를 건너뛰는(Offset) 비용조차 커지게 됩니다.
그때는 "마지막으로 조회한 ID보다 작은 것 20개(WHERE id < lastId LIMIT 20)" 방식인 No-Offset(Cursor-based) 방식으로 리팩토링할 계획입니다.
하지만 현재 10만 건 수준에서는 Index 타는 Offset 방식으로도 0.1초 대의 성능이 나오기에, 조기 최적화(Premature Optimization)를 피하고 우선순위가 높은 기능부터 개발하기로 결정했습니다.
Q. 데이터 정합성 문제는 없나요? :
사용자가 스크롤을 올리는 도중에 새로운 메시지가 오면, Offset이 밀려서 중복된 메시지가 보이거나 누락될 수 있습니다. 다행히 현재 구현된 Slice 방식과 프론트엔드의 중복 제거 로직으로 어느 정도 커버가 되지만, 완벽한 정합성을 위해서는 위에서 언급한 Cursor 기반 페이징이 답입니다.