Operating System - Segmentation[Memory Virtualzation](5)
Segmentation
--> Motivation? base and bound approach의 비효율성
--> 연속적인 물리적 메모리 공간에 매핑해야 한다는 점
--> 1. Wasted Memory 메모리 낭비
--> 2. Big Address Space Not Supported 여러 프로세스가 들어오면 다 못들어간다
--> 3. Duplicated Code Section 수행에 필요한 공통적인 코드가 겹치기에 공간이 낭비
Segmentation?
--> 주소공간을 세그먼트로 나누고 각각의 세그먼트들을 독립적인 물리적 메모리에 매핑시키는 방법


세그먼트는 특정길이의 주소공간에서 연속적인 부분
--> Locally-defferenct segment : Code, Stack, Heap 존재
구현?
명시적 접근(Explicit Approach)
--> 가상주소의 상위공간 몇 비트를 기준으로 주소공간을 세그먼트로 자름
--> MSB(Most Significant Bit - 최상위 비트), LSB(Least Significant Bit - 최하위 비트)

1. 이 예에서 왜 2비트는 다른 세그먼트로 분리되었나?
--> Segment ID값으로 분리되기위해 --> 만약 한 비트라면?? 코드와 힙 영역이 같은 세그먼트로 합쳐질 것 --> ID값으로 분리할 수 없기에
2. 왜 12비트는 Offset으로 사용되었나?
--> 하나 메모리 주소가 가리키는게 1byte, 오프셋이 12bit로 이루어져 있으므로 2^12byte 가리킬 수 있다
--> 26K + 104만큼이 Offset
--> 즉 가리키는 물리적 주소의 Base가 26K이고, 여기서 논리적 주소값을 더한게 Offset 만큼이므로 --> Offset은 000001101000 --> 2^6 + 2^5 + 2^3 = 104만큼 차지
--> Offset이 가리키는 논리적 주소
--> Offset이 104로 바운드(2K) 보다 적으니 정상적 --> 만약 정상적이지 않으면 exception이 발동
만약 code sharing 되는 library 코드를 어느 프로세스가 바꿔놓는다면?? 안된다
--> read는 가능하지만 write 불가하게 protection 거쳐야
스택은 뒤로 증가(즉 밑으로 증가) - dynamic하기에
--> Extra Hardware가 필요 --> 하드웨어가 세그먼트가 어느방향으로 커지는지 체크함
--> 해당 비트가 1이면 위로(positive direction), 0이면 아래로(negative direction)
코드, 힙, 스택 각각의 base/bound register 필요(PCB내에 존재 - OS가 관리)
stack은 보수를 취해서(negative) - 위에서 아래로 가면서 점유
--> Stack은 주소의 가장 높은부분에 위치하기에 아래로 가면서 점유하기에 Offset에 2의 보수를 취해주어야 한다

해당 상황에서 Offset 보수를 취하면? 010111111111 = 1535 --> Bound(2K = 2000)보다 아래기에 ok
공통으로 쓰이는 코드?
Code Sharing - ex. library --> 여러 프로세스가 공유하는 코드이기에, 임의의 프로세스가 이를 변경해서는 안된다 --> 권한을 주는 방식으로(permission bit, protection bit)
--> Protection bit가 필요하다! read만 가능하도록 도와줌(Permission bit를 둠으로써)

하드웨어는 Implicit Apporach 즉 암시적인 접근으로 주소가 어떻게 생성되었는지 알 수 있다
--> PC에 의해 생성? --> Code segment
--> Stack이나 base pointer에 기반을 둔다? --> Stack Segment
--> 이외 다른 주소 --> Heap Segment
Segmentation의 문제
OS가 Context Switch 한다면
--> Segment registers는(base and bound registers pair) 저장되고 관리되엉 ㅑ한다
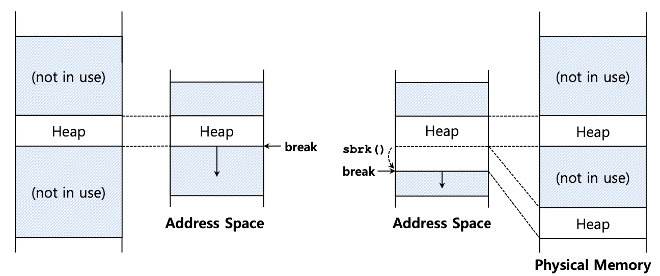
세그먼트 사이즈를 바꾸는 방법? 더 많은 heap 영역 - malloc() 혹은 sbrk() system call
물리적 메모리에서 free space를 관리하는 방법?
--> OS는 물리적 메모리에서 세그먼트 별로 free space 찾을 수 있어야
--> Fragmentation
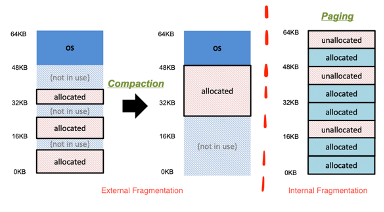
Fragmentation
--> 즉 전체 여유공간은 되는데, 쪼개져 있기에 메모리 공간 하나에 모여져있지 않고 파편화(fragmentation) -- 총량은 24kb, freespace 16, 4, 4 --> 20kb가 들어온다면? --> compaction을 거쳐 묶어서 재배치
--> Compaction이 잘 사용되지 않는 이유 --> Costly, 비싸다
--> 프로세스를 멈추고, 데이터를 카피해둔 후, 세그먼트 레지스터 값을 바꾸어야 한다
--> 즉 이미 메모리에 써져있던 영역을 다시 읽고 다시 써야한다는 --> cpu 성능은 메모리 접근해서 읽고 쓸때 떨어지므로 - 성능이 떨어진다
--> 이러한 것을 없애기 위해서 나온게 paging이기도 --> 정해진 크기별 세그먼트로 나누어 관리해 external fragmentation을 방지하는 것
--> 근데 paging도 Internal Fragmentation이라는 문제점이 있다
--> 페이지 단위로 매핑 --> 페이지 단위 - 즉 단일 사이즈로
--> 15kb 요청 - 각 8kb인 페이지 2개 할당 --> 1kb의 잉여 메모리 공간
Segmentation의 세분화 정도 - pdf만 보기 중요하진 X
Fine-Grained - 작게작게 관리
Coarse-Grained - 큼직큼직 관리
요약
Segmentation은 물리적 메모리 할당에서 효율적
--> No longer wasted Memory
--> Big Address Space Supported
--> Code Sharing Supported
Segmentation의 문제점
--> External Fragmentation
--> 해결책 : Paging
--> Paging의 문제점 - Internal Fragmentation
heap영역을 할당하는 API - malloc()

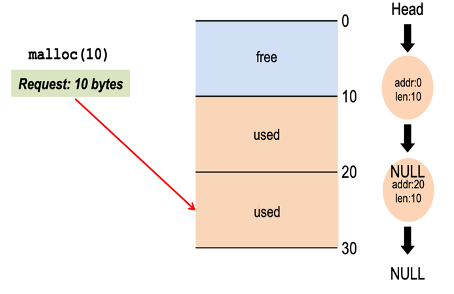
만약 30-byte size의 힙이 있다고 가정,
malloc(10)해서 heap영역의 10bytes를 할당(allocate) --> 10에 할당 요청? --> 근데 사용중임(10~20)
--> 20 ~ 30부분에 재할당해서 20~30이 used로 바뀌고, 이후 5 할당 요청
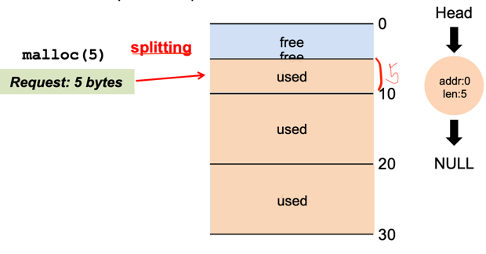
0~10 중에서 split된 5 ~ 10에 할당 --> 이후에 다 사용하면 free(5)
만약 heap이 space를 넘어서 수행된다면? --> sbrk(10)라는 시스템콜 --> OS가 10바이트끼리 뭉쳐서 20byte 사이즈가 돌아갈 수 있도록 바꿔준다
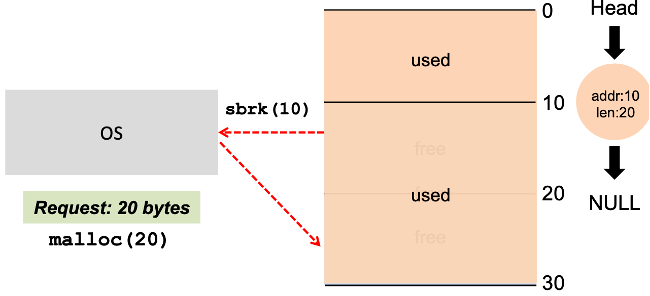
그러면 malloc(20)해도 돌아갈 수 있다
--> 근데 논리적으로 같은 공간에 두는 것일 뿐 물리적으로 같이 만들어두는 것은 아님
만약 메모리의 chunk(큰 덩어리)가 요청되면, 라이브러리는 요청을 감당할만하게 충분히 큰 사이즈의 chunk를 찾는다 --> Library는 큰 Chunk를 두개로 Split 할 것(하나는 request 처리용, 하나는 free chunk로 걍 남겨둠) 그리고 list의 free chunk 사이즈를 shrink(축소)
예시)
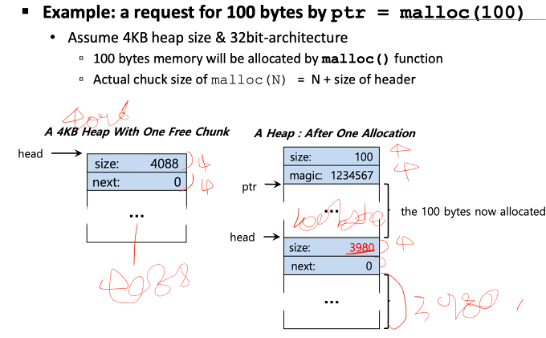
힙 사이즈를 4KB로, 32비트 아키텍쳐를 사용중이라고 가정
32bit --> 각 크기가 4Byte / 64bit는 각 크기가 8Byte
첫 번째 --> 4096Byte(4KB) - 4Byte - 4Byte = 4088Byte
두 번째 --> 4096Byte(4KB) - 4Byte - 4Byte - 100Byte(alloacted된 영역) - 4Byte - 4Byte = 3980Byte
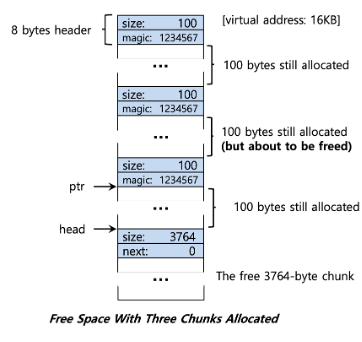
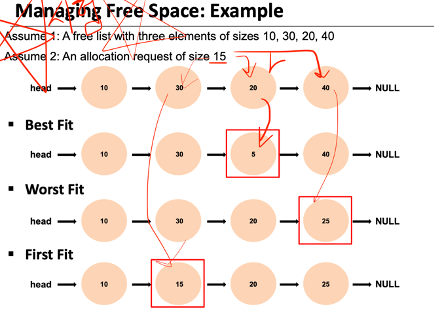
managing free space - free space를 제공할 것인지에 대한 기준
- best fit
: 요청한 크기와 가장 유사한 크기를 찾아서 제공 - free chunk 중 요청한 크기와 맞거나, 조금 더 큰 정도
--> 가장 적은 차이로 남기기 위해
- worst fit
: 제일 큰 잉여메모리 남기는, 가장 차이가 큰 크기 제공 - free chunk중 가장 큰 크기
--> 또 제공할 수 있도록 free space를 가능한 많이 갖기 위해서 쓰는
- First fit
: 요청하는거 보다 크면 무조건 바로제공 - 요청하는 것 보다 큰 first chunk를 바로 제공
--> 속도, 빠른 할당
- Next fit
: 요청하는거 보다 크면 제공 --> 목록을 구걸하는게 아닌 보고있던 것을 바로 제공
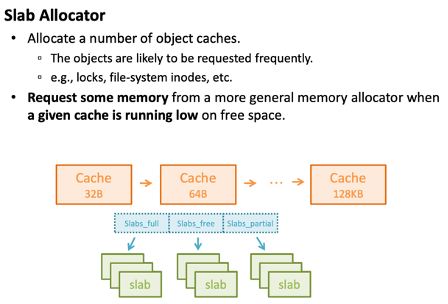
Slab Allocator
--> 자주 쓰이는 것들을 분석해 메모리에 담아두는 정책
--> 자주 쓰이는 것? 보통 캐시 메모리에 있다
--> 메모리에 최소한 접근하는데 그치기 위해서, 가장 많이사용 되는 적은 용량의 빠른 메모리에 올려논 게 캐시 메모리
--> 즉, 캐시 메모리에 있는 것들은 빈번히 사용되는 것
--> 캐시 메모리에 있는 데이터들을 보고, 그에 맞게 크기단위를 구분짓는다
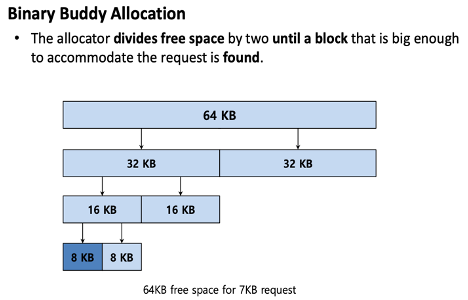
Buddy Allocation
--> Free space를 제공하되, 가능한 나중에 return이 되었을 때 쉽게쉽게 합쳐서 큰 메모리공간을 쉽게 확보하겠다는 목적으로
--> 그니까 64kb 가 있는데 7kb만큼 요청이 온다 --> 통채로 안주고 나누고, 나누고, 나눠서 8kb만큼만 주고 끝낸다
--> 8kb가 free가 되어 return된다 --> 병합 --> 그냥 8kb 빈거랑 병합, 16kb빈거랑 병합, 32kb 빈거랑 병합 이런식으로 다시 되돌아가는 --> 그렇다고 해서 꼭 똑같은 사이즈랑 병합하진 않음 --> 보통 그래도 2진트리 방식으로 하긴함
--> 실제로 많이사용