데이터베이스 - 데이터와 정보, 데이터베이스, DBMS
데이터?
현실세계로부터 단순한 관찰이나 측정을 통해서 수집된 사실이나 값
--> 숫자는 물론이고 문자, 이미지, 영상등을 포함함
--> 데이터는 처리되지 않은 값이고 정보는 데이터를 처리하여 얻은 값
--> 정보의 유용성을 위해서는 데이터가 정확하고 최근의 것이어야 함
정보?
의사결정을 할 수 있께 하는 지식으로서 데이터의 유효한 해석이나 데이터 상호간의 관계를 말함
--> 정보는 데이터를 처리해 얻은 결과
--> 즉, I = P(D) --> Information = Processing(Data)
--> 정보 추출 방법을 데이터 처리(Data Processing) 또는 정보처리(Information Processing)라고 한다
* 데이터는 현재의 당면한 문제와 관련되고 필요시 언제나 이용될 수 있도록 수집, 조직, 저장되어야 함
ex. 제조업 회사의 재고관리시스템
--> 적정 재고를 위한 데이터 제공
--> 수요와 공급 추세에 따른 적정 생산 계획 수립
--> 적정량의 원료 구입 가능
--> 정확하고 최근의 정보는 조직체의 효과적인 운영을 위해 필수적임
정보시스템
--> 조직체에 필요한 데이터를 수집, 조직, 저장한 후 필요시 유용한 정보를 생성하고 분배하는 수단

경영정보시스템(MIS : Management Information System)
--> 기업의 경영관리를 위한 가장 정확하고 최신의 정보를 제공하는 수단으로 사용되는 정보시스템
사용목적에 따른 정보시스템의 분류?
- 생산관리 시스템
- 은행관리 시스템
- 병원관리 시스템
- 의사결정지원 시스템
- 지식관리 시스템
데이터 처리 시스템
--> 정보시스템은 실제로 데이터를 처리하는 서브시스템을 기초로 구성
--> 데이터의 처리 형태에 따라 구분
--> 일괄처리 / 온라인처리 / 분산처리
일괄처리?
급여 명세서나 납세 고지서 출력과 같은, 번호와 같이 순차 접근 방법을 사용하는 업무에 적합
--> 그렇기에 일괄처리 방식은, 작업들을 한데모아 일괄적 처리를 하고(낮은 처리비용),
시간당 처리되는 작업 수가 많음(높은 시스템 성능)
--> 사전 준비 작업이 필요하다
--> 원시 데이터의 수집과 분류, 정리하여 파일에 수록해야

온라인 처리 시스템?
온라인 실시간 처리 : 데이터 생성 후 컴퓨터는 즉시 처리
ex. 항공권 좌석 예약, 은행 입출금 업무, 쇼핑몰
--> 사용자 중심의 처리 방식
--> 데이터 분류 및 정리 작업을 절약시켜줌 / 입력 시 데이터 오류 즉시 발견 / 질의, 갱신을 통한 데이터 최신성을 편리하게 유지
--> 통신제어기가 필요(구조가 복잡), 응답시간 최소화 필수(높은 처리 비용), 보수, 유지, 회복이 매우 복잡

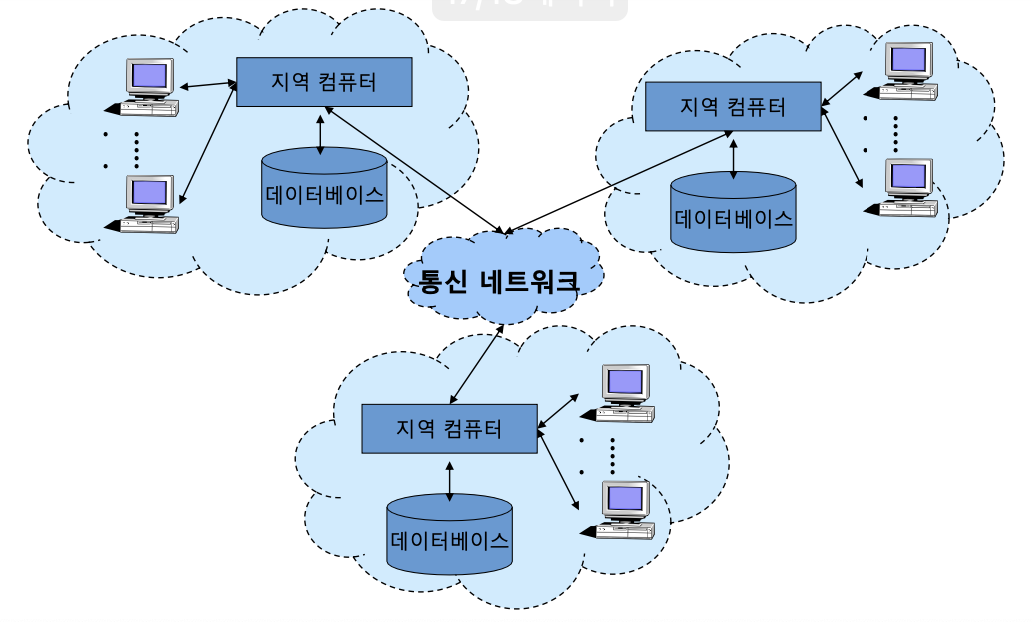
분산 처리 시스템?
네트워크로 연결시켜 마치 하나의 시스템 처럼 데이터를 처리
--> 분산처리기 : 지역컴퓨터 / 분산 데이터 베이스로 나뉘어
--> 통신 네트워크 : 논리적으로 한 시스템 처럼 운영되도록 하는 네트워크
--> 분산 데이터베이스 : 데이터는 가장 많이 이용되는 장소에 저장, 사용자 입장에서는 논리적으로 하나의 데이터베이스로 취급되도록 함
분산 처리 시스템의 이점
- 지역 문제 발생에 대한 신속한 조치
- 지역 업무에 대한 명확한 책임 구분
- 새로운 응용에 대한 모듈식 구축 용이
- 장애에 대한 자원 재편성으로 신뢰성 증대
- 상이한 하드웨어 허용으로 지속적 확장 발전 가능
--> 컴퓨터 및 통신비용이 저렴해지고 신뢰성과 융통성이 증진됨에 따라 분산 체제는 보편화되고 있음
데이터베이스란?
어느 한 조직의 여러 응용 시스템들이 공용할 수 있도록 통합 및 저장된 운영데이터의 집합
--> 데이터베이스는 통합 데이터(integrated data)이다 : 원칙적으로 중복을 배제 / 통제된 중복이 되어야
--> 데이터베이스는 저장 데이터(stored data)이다 : 저장매체에 저장된 데이터를 말한다
--> 데이터베이스에 저장되어 있는 데이터는 운영데이터(operational data)이다 : 조직의 기능을 수행하기 위해 반드시 유지해야 될 데ㅣㅇ터
--> 데이터베이스는 공용 데이터(shared data)이다 : 여러 응용 시스템들이 공동으로 이용하는 데이터
데이터베이스의 특성
- 실시간 접근성 : 비정형 질의어(query)에 대한 실시간 처리로 응답 가능
- 계속적인 변화 : 동적이다, 즉 삽입, 삭제, 갱신으로 항상 그 내용이 변함
- 동시공용 : 여러 사용자가 동시에 접근 가능
- 내용에 의한 참조 : 내용 검색(ex. 중간 성적이 85점 이상인 학생 검색)이 가능하다
데이터베이스의 개념적 구성
데이터베이스는 개념적으로 개체(entities)와 관계(relationships)로 구성되어 있음
--> 개체?
--> 현실세계에 대해 사람이 생각하는 개념이나 정보의 단위
--> 하나의 개체는 하나 이상의 속성 즉, 애트리뷰트로 구성

학생이라는 개체 : 학번, 성명, 전화번호라는 3개의 속성들로 구성. 여기서 속성들은 개체가 가지고 있는 성질이나 상태를 나타낸다
--> 각 속성들 학번, 성명, 전화번호는 그 자체로는 큰 의미 있는 정보를 제공해주지 못하지만, 이것들이 모여 '학생'이라는 개체를 구성하여 표현할 때는 상당한 의미를 제공
<20181234, 김철수, 010-0000-0000>
--> 학생 개체의 한 값, 개체 인스턴스(entity instance) 또는 개체 어커런스(entity occurrence)라함
--> 개체 집합 : 개체 인스턴스들의 모임
--> 개체 타입 : 학번, 성명, 전화번호와 같은 속성 이름으로만 기술된 타이틀 레코드
--> 개체 타입은 논리적인 형태를 말하고 개체 인스턴스들은 데이터베이스에 저장되는 구체적인 값들
관계?
관계도 데이터베이스에 저장되어야 한다
--> 속성관계 : 속성들 간의 관계
--> 개체관계 : 개체 집합 간의 관계
--> 데이터베이스에서는 일반적으로 개체 관계만 명시적으로 취급하고 속성 관계는 레이블 없이 묵시적으로 표현한다

관계는 정보를 추출하는데 중요한 역할을 한다
--> "학번이 20181234인 학생의 전화번호를 검색하라" -> 속성관계를 통해서 정보를 검색
--> "학번이 20181234인 학생의 지도교수 성명을 검색하라" -> '지도'라는 개체 관계 통해 연관성을 고려하여 정보를 검색

기존 파일 시스템의 문제점?
데이터 종속성과 데이터 중복성

데이터 종속성
--> 응용 프로그램은 데이터의 구성이나 접근방법에 맞게 작성되어야 함
--> 데이터의 구성이나 접근방법을 변경할 때는 해당되는 응용 프로그램도 같이 변경되어야 됨
데이터 중복성
--> 같은 내용의 데이터 일지라도 각 응용 프로그램마다 별도의 파일로 만들어 중복되는 경우가 많이 생김, 이와 같이 중복되게 저장 관리되는 것을 데이터 중복성이라 함
데이터 중복성이 나쁜 이유
- 일관성 : 일관성이 없다 = 데이터 간의 불일치
- 보안성 : 같은 데이터에 대해 같은 수준의 보안 유지가 어렵다
- 경제성 : 추가적인 저장 공간, 비싼 갱신 비용
- 무결성 : 데이터의 정확성을 유지하기 어렵다
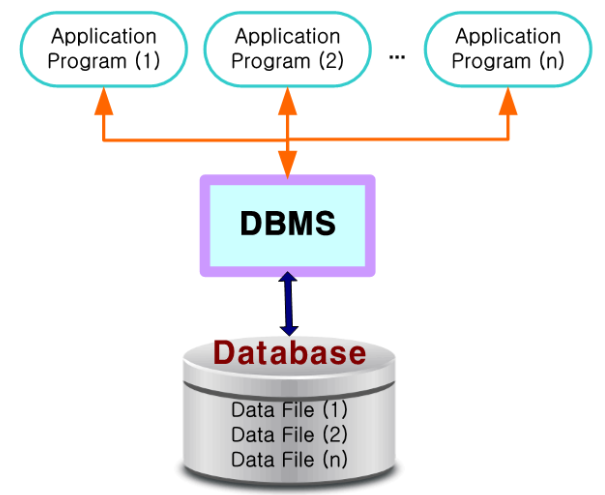
DBMS란?
파일 시스템에서 야기되는 데이터 종속성과 중복성의 문제를 해결하기 위해 제안된 시스템
--> 응용 프로그램들이 데이터베이스를 이용하기 위해서는 DBMS를 통해서만 가능
--> 데이터베이스의 구성, 접근방법, 관리유지에 대한 모든 책임을 DBMS가 지고 있다
DBMS의 필수 기능
1. 정의 기능
--> 데이터베이스 구조를 정의할 수 있는 기능
2. 조작 기능
--> 데이터베이스를 접근하고 조작할 수 있는 기능
3. 제어 기능
--> 정확성과 안전성을 유지할 수 있는 기능
--> ex. 갱신을 정확하게 수행, 보안, 병행 제어
DBMS의 장단점
- 장점 : 데이터 중복의 최소화(제어된 중복만 허용) / 데이터의 공용 / 데이터의 일관성 유지(중복을 줄임으로써 변경 시 불일치 최소화) / 데이터의 무결성 유지(정확성, 입력 시 에러 체크 ex. 전화번호) / 데이터의 보안 보장 / 표준화 용이(중앙 통제에 의한 표준화) / 데이터의 독립성 제공(구현상의 세부 사항을 사용자에게 숨김)
- 단점 : 운영비의 증대(고가의 제품) / 자료 처리 방법이 복잡(상이한 데이터 타입, 고급 프로그래머 필요 필요 / 백업과 회복 기법이 어렵다(장애 발생 시 곤란) / 시스템의 취약성(일부 장애 -> 전체 시스템 마비)
데이터 독립성?
데이터의 논리적인 구조나 물리적인 구조가 변경되더라도 응용 프로그램에는 영향을 주지 않는 것
1) 논리적 데이터 독립성
: 논리적 구조를 변경시키더라도 기존 응용 프로그램들에는 영향을 주지 않는 것
2) 물리적 데이터 독립성
: 저장 장치나 새로운 접근기법의 개발로 성능 개선을 위해 물리적 구조를 변경하더라도 이를 이용하는 응용 프로그램들에는 영향을 주지 않는 능력. 이는 논리적 구조에는 영향을 주어서는 안됨 / 저장 장치의 효율적 개발이 가능
이는 하나의 논리적구조로붜 여러가지 다양한 물리적 구조를 지원할 수 있는 사상능력이 있어야 가능

DBMS의 발전 과정
- 제 1세대 DBMS
--> IDS : 최초의 범용 DBMS, 네트워크 데이터 모델의 기초
--> IMS : 계층 데이터 모델의 기초
- 제 2세대 DBMS
--> 관계형 데이터 모델, SQL
--> 상용 RDBMS : Oracle, SQL-Server, My SQL, DB2, Informix, Sybase
- 제 3세대 DBMS
--> 객체지향 DBMS(OODBMS)
--> 객체관계형 DBMS(O-RDBMS)