Operating System - CPU Virtualization & Scheduling(3)
Process Scheduling
: ready queue 내의 프로세스들의 순서를 정하는 것
--> multi programming OS의 바탕
--> CPU scheduling, Job scheduling 이라고도 함
어떤 스케쥴링이 가장 좋은가?
- user-oriented : Turnaround Time(TAT), Response time, Deadline,,
- system-oriented : Throughput, Processor utilization
- Fairness, ,,,
TAT : 어떠한 프로세스가 시작해 끝날 때 까지의 시간
Response time : 무언가를 실행했을 때 첫 번째 반응이 올때 까지의 시간
Throughput : 서비스 제공자가 중요히 여기는, 얼마나 규칙적으로 잘 결과가 나오는지
* TAT, Response time : 산술평균으로 구하기
* Throughput : 조화평균으로 구하기(인터넷에서 알아보고 문제 탐색해야)
모든 기준을 동시에 충족하는 스케쥴링은 없다
: response time을 개선시키기 위해 잦은 context switching이 일어나면 overhead가 많아지고 system throughput이 안좋아 질 수 있기때문
프로세스 스케쥴링을 더 자세하게 나누는
롱텀 / 미드텀 / 숏텀
long term : 실제 메모리에 몇 개의 프로세스를 올리고 몇 개를 내보낼 지 결정하는 것, 멀티프로그래밍의 정도를 제어 - 리소스에 초점
mid term : 메모리와 디스크 사이 스와핑 관련해 결정
short term : 메모리 내 레디큐에 있는 프로세스 중 다음 cpu가 수행해야 하는 프로세스로 어떤 프로세스에 권한을 줄 지 결정하는 것(dispatcher이라고도 함)

Scheduling
- Preemptive scheduling
: running 중 프로세스 멈추고 ready로 옮기는 것
--> Flexibility, adaptability, performance improvements
--> High context switching overhead를 고민해야
- Non preemptive(cooperative) scheduling
: 중간에 프로세스를 멈추지 않고 끝날 때 까지 cpu가 수행
--> low context switch overhead
--> response time이 좋지않음을 고민해야
cpu burst
: cpu가 동작하는 구간
I/O burst
: I/O 요청이 동작하는, 즉 cpu가 잠깐 멈추는 부분

스케쥴링 기법을 결정할 때 사용하는 workload로 몇 가지 가정을 한다
: 현 상황에 대한 가정을 만들어 가장 기본적인 토대에서 하나 씩 가정을 지워가며 복잡하게
가정들
1. 각 프로세스의 러닝타임은 동일하다
2. 모든 job들은 동시에 도착한다
3. 모든 job들은 CPU만을 필요로 한다(I/O가 없다고 가정)
4. 각 job들의 수행시간은 알려져있다
5. 한번 수행되면 중간에 멈추지 않는다(Non-preemptive, Cooperative)
스케쥴링 선택의 기준 - TAT(Turnaround Time)

response time을 초점으로 나온 Round Robin 스케쥴링 방식
스케쥴링 기법 - RR(Round Robin)
: preemptive한 기법으로, time slice를 가지고 수행시간에 맞게 프로세스를 switching하여 response time을 개선(공정하고, response time엔 good, 하지만 TAT에는 poor함)

Incorporating I/O
: I/O의 개입없다는 가정을 지우기 위해
--> 어떻게 해결?
--> 프로세스 A를 실행할 때, I/O exception이 발동되면 도착할 때 까지 프로세스 B를 실행시킴으로서
MLFQ(Multi Level Feedback Queue)
: 프로세스의 run time 모르지만, 이를 고려해 스케쥴링 기법으로 만듦
--> 수행을 기다리는 queue가 여러 개(멀티레벨)
--> 기본적 목표로 TAT최소화와 Response time 줄이는 방향
--> 우선권을 부여하여 높은 순으로 수행하고 같은 경우 RR(time slice 할당)로 수행

상황에 따른 가정
1. 수행 중 I/O를 요청하는 job(cpu 자체 수행이 적은)
: Interactive한 사용자가 주로 사용하는 job
--> time slice를 짧게 둠
--> Response time이 중요하니 RR으로
--> priority 높은 우선순위로 줌
2. 수행 중엔 계속 cpu만 하는(cpu 자체 수행 많은)
: 가능한 long time slice로 잡아도 됨
--> TAT에 좋게 구현
--> priority 낮은 우선순위로 줌(높은 우선순위로 주면 long time slice로 인해 계속 미뤄짐)
MLQ의 문제점? 큐 끼리 움직일 수 없다
MLFQ로 룰을 보완
Rule 3: job이 시스템에 들어오면 가장 높은 우선순위로
Rule 4a : job이 해당레벨 time slice를 소진 시 낮은 priority로 이동
Rule 4b : job이 끝나면 priority가 내려가는게 아닌 해당 큐의 마지막으로 이동



example 1: 짧은 거 순서대로
example 2 : A수행 중에 B가 --> 제일 높은 priority로 가서 수행
example 3 : B가 rule4b에 의해 계속 Q2에 있고 I/O요청을 계속 하고 있으므로 Q2에서 계속 수행
MLFQ의 문제점
:
1. Starvation
--> 특정 프로세스가 실행되지 못하고 계속 Q2에 있는 것만 실행되는 빈곤
2. priority를 내릴 방법만 가지고 있고 프로세스 수행 중 메인 기준(TAT, response time) 이 중간에 달라지면 조정불가
3. 전체 시스템의 cpu를 독점할 수 있는 기회
--> time slice 99%만 사용하고 1%를 남겨서 의도적으로 I/O 작동을 불러오는 방식 통해서
Priorty Boost
: boost를 통해 낮은 priority에 있던 job들을 주기적으로 올려줌
--> 1. Starvation과 2. 조정을 해결 가능
Better Accounting
: 안끝나면 priority를 내려버리는 방식
--> 3. 독점을 막을 수 있다
MLFQ 룰 요약
- Rule 1 : If Priority(A) > Priority(B), A runs (B doesn't)
- Rule 2 : If Priority(A) = Priority(B), A & B run in RR
- Rule 3 : When a job enters the system, it is placed at the highest priority
- Rule 4 : Once a job uses up its time allotment at a given level(regardless of how many times it has given up the CPU), its priority is reduced(i.e., it moves down on queue)
- Rule 5 : After some time period S, move all the jobs in the system to the topmost queue
Proportional-share Scheduling
: fair-share scheduling이라고도 하는데, 프로세서(CPU)의 권한을 받는데 있어서의 fairness를 보장하기 위해 사용하는 스케쥴링 기법, 2가지 기법이 있다
--> 1. Lottery Scheduling : 프로세스가 다음 연산을 수행하기 위한 결정에서 랜덤 선택
--> 2. Stride Sheduling : 각 프로세스가 이전에 얼마나 CPU를 사용했는지 확인하고, 덜 사용한 프로세스에 CPU 권한을 부여
기본적인 배경 : Tickets Represent Your Share
- 티켓 : 프로세스가 받는 자원의 비율 - 티켓의 퍼센트는 시스템 리소스에서 차지하는 비율을 나타냄
--> 즉 어떤 프로세스의 티켓이 많을수록, 이길 기회(권한을 부여받을 기회)도 많다
ex. Process A has 75 tickets = 75 / 100 --> receive 75% of the CPU
Process A has 25 tickets = 25 / 100 --> receive 25% of the CPU
* Starvation을 막을 수 있다
* 하지만 정확히 75개 티켓이라고 정확하게 100번 시행했을 때 75번이 수행되는 확정은 아니다, 시도가 계속될 수록 75%에 가까워진다는 비율이라는 것
Lottery Scheduling
: 리소스를 놓고 경쟁하는 모든 티켓들의 집합에서 티켓을 Random selection
--> Lottery를 통한 스케쥴링은 확률적으로 공평(fair)
--> 각 티켓(프로세스가 아님)은 선택될 확률이 모두 같다
--> 리소스가 선택될 예상 확률(ready queue의 프로세스가 선택될 확률)은 그들이 가진 티켓에 비례해서 생각할 수 있다
--> starvation을 피하기 위해서, 모든 job들은 최소 1티켓을 가진다(everyone makes progress)
--> 실제 할당될 비율은 할당 예상 비율과 정확하게 일치하지 않을 수 있다


Ticket Mechanisms : Ticket Currency / Ticket Transfer / Ticket Inflation / Deflation
Ticket Currency
: 티켓들의 지역적 집합느낌(화폐 속의 화폐)
--> 각 유저들은 임의로 화폐를 변경해서 배분가능
--> 스케쥴러는 자동적으로 지역적 화폐(local currency)를 전역적 값(global value-즉 tickets)로 바꿈
Ticket Transfer
: 프로세스는 티켓들을 다른 프로세스로 전달할 수 있다
--> basic idea : 만약 다른 어떤 요소에 의해 실행이 막힌 경우, 가진 ticket을 줄 수 있음
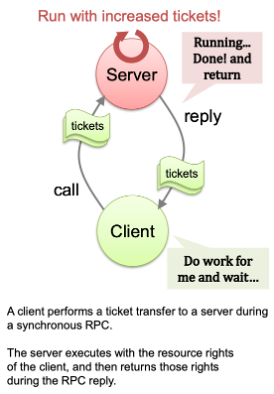
--> client-server setting시 유용 --> server는 CPU time을 client에게 tickets을 받음으로서 더 많이 가지기 가능
--> 클라이언트를 대신해서 작동할 때 server의 성능 최대화를 위해
Ticket Inflation / Deflation
: 프로세스는 자신이 가진 티켓의 수를 잠시동안 늘리거나 줄일 수 있음
--> 어떤 프로세스가 더 많은 CPU 시간이 필요한 경우 ticket 수를 boost 가능
--> 그룹으로 된 프로세스가 서로를 신뢰할 때 의미가 있다
--> greedy한 프로세스는 스스로에게 많은 티켓을 줄 수 있다
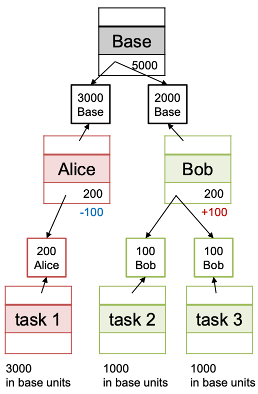
Lottery scheduling의 핵심 매커니즘
: 간단한 list 기초 lottery
--> step 1. winning ticket으로 무작위 숫자를 고른다(0에서 total ticket-1 까지의 수에서)
--> step 2. 해당 티켓을 가진 job을 찾아낸다
---> 반복을 줄이기 위하여 리스트를 내림차순으로 정렬해 만들어야
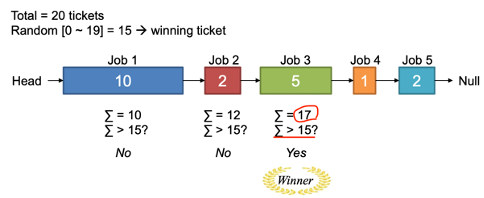
예시에선 0 ~ 19의 값에서 15를 골랐고, 15 나온 프로세스들의 ticket값을 모두 sum 했을 때 15가 넘으면 winner가 되기에 3번째 job이 winner가 되어 cpu권한을 받게 된다
Fairness
- U : unfairness의 정도
--> U = 첫 번째 job이 완료된 시간 / 두 번째 job이 완료된 시간
ex. First job finishes at time 10, First job finishes at time 20
--> U = 10 / 20 = 0.5
--> U는 1에 가까울 수록 각각의 job이 시간차가 적게 나면서 완수된다고 볼 수 있다
--> 1이 되면 완전히 fair한 것

fairness study
--> 만약 job이 짧은 시간 수행되면 될 수록 lottery scheduler은 낮은 공평성
--> 만약 job이 긴 시간 수행되면 될 수록 lottery scheduler은 높은 공평성

Lottery Scheduling의 장단점
- 장점 : 심플하다
--> 쉽게 이해할 수 있고 동적인 작업(dynamic operation) 지원
- 단점 : 확률을 보장하기 어렵다
--> 짧은 run time에 있어서 낮은 정확성 / 티켓이 많은 A 프로세스 계속 밀린 탓에 B는 response time이 밀린다
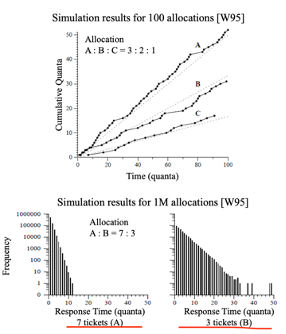
이러한 단점들(확률 보장의 어려움과 response time 변동성)을 극복위해 Stride Scheduling
Stride Scheduling(보폭 스케줄링)
: 각 프로세스의 Stride를 고려
--> (A large number) / (the number of tickets of the process)
--> ex. A large number = 10,000 / Process A has 100 tickets, Process B has 50 tickets
---> stride of A is 100(10,000 / 100), stride of B is 200(10,000 / 50)
---> 즉, stride는 티켓 수에 반비례한다(티켓 수 많으면 많을 수록 수행을 많이 했을 것이기에)
Pass
--> 각 프로세스의 진행상황을 추적하는 값
--> process가 run될 때 해당 process의 stride 만큼 증가된다(진행상황이 늘어났기에)
그래서 가장 낮은 pass를 가진 값의 프로세스에 cpu 권한을 준다 --> process에 cpu부여가 많이 부여되지 않았다는 의미이므로
간단하게, 말하면 Stride Scheduling은
step 1. The process with the minimum pass is selected
step 2. If more the one process has the same minimum pass value, then any of them may be selected(randomly)
step 3. Run the process and increase the pass of the process
--> 이후 계속 반복

Stride Scheduling의 장단점
- 장점 : 확실하게 보장된다는 점 / 짧은 run time 프로세스에 대한 좋은 정확성 / response time의 변동성이 낮음
- 단점 : 동적인 작업에 있어 리소스의 독점문제가 발생 / 글로벌 변수들의 추가가 필요(global tickets, stride, pass)
독점문제?(Monopoly Problem)

--> 20000 pass값을 가진 A, B, C와 50 pass값을 가진 D
--> 계속 D가 Cpu 권한을 계속 가져서 독점하게 됨(pass값이 계속 낮은데 50씩 increase되기에 - 20,000까지 한참 남음)
